It’s been fascinating watching the operational world change over the years. We started out by racking and stacking anything that needed to run. We wisened up a bit and started using virtual machines. More recently we’ve moved into containerization. Surely, that’s the pinnacle of operational excellence.
As of now, that’s a yes, with a but. That “but” really comes into play when you’re dealing with messaging systems. This is when when you’re trying to operationalize producers, consumers, and consumer/producers.
Operationalizing Consumers and Producers
If you’ve ever operationalized a consumer, certain producers, or consumer/producers you know how tedious it is. If you haven’t let me briefly describe it.
Every single one of your consumers, producers, and consumer/producers needs to be a separate process. This just gets unwieldy on several levels. How do you deploy these processes? How do you update them with newer versions? How do you know each required process is running?
Maybe you’re lucky and you can use containers. That makes things a little easier. You have a better mechanism to spin up and monitor each process.
Even with containers, you still have a ton of duplicated code. Containers only solved part of the problem. Now you have to copy-and-paste Docker files and spin up YAMLs with minimal changes. You still have the copious boilerplate code that configures and starts the processing.
We’ve solved a few issues, but didn’t really solve the whole issue. This is because these consumers, producers, and consumer/producers all present a slightly different problem.
Boiling Down the Problem
Let’s boil our problem down the absolutely crucial components:
- We need to receive data from one or more topics
- We need to run our code
- We need to output data to one or more topics
All of the other code that doesn’t support those 3 objectives is boilerplate code. This includes things like defining our main method or our Dockerfile. In an ideal world, we’d just focus on those 3 things.
You might have seen the same or similar concept called serverless computing. This is an approach that’s popular with the cloud providers. There are several parallels with Pulsar Functions. In both systems, you use a specific API and all underlying operations are taken care of for you.
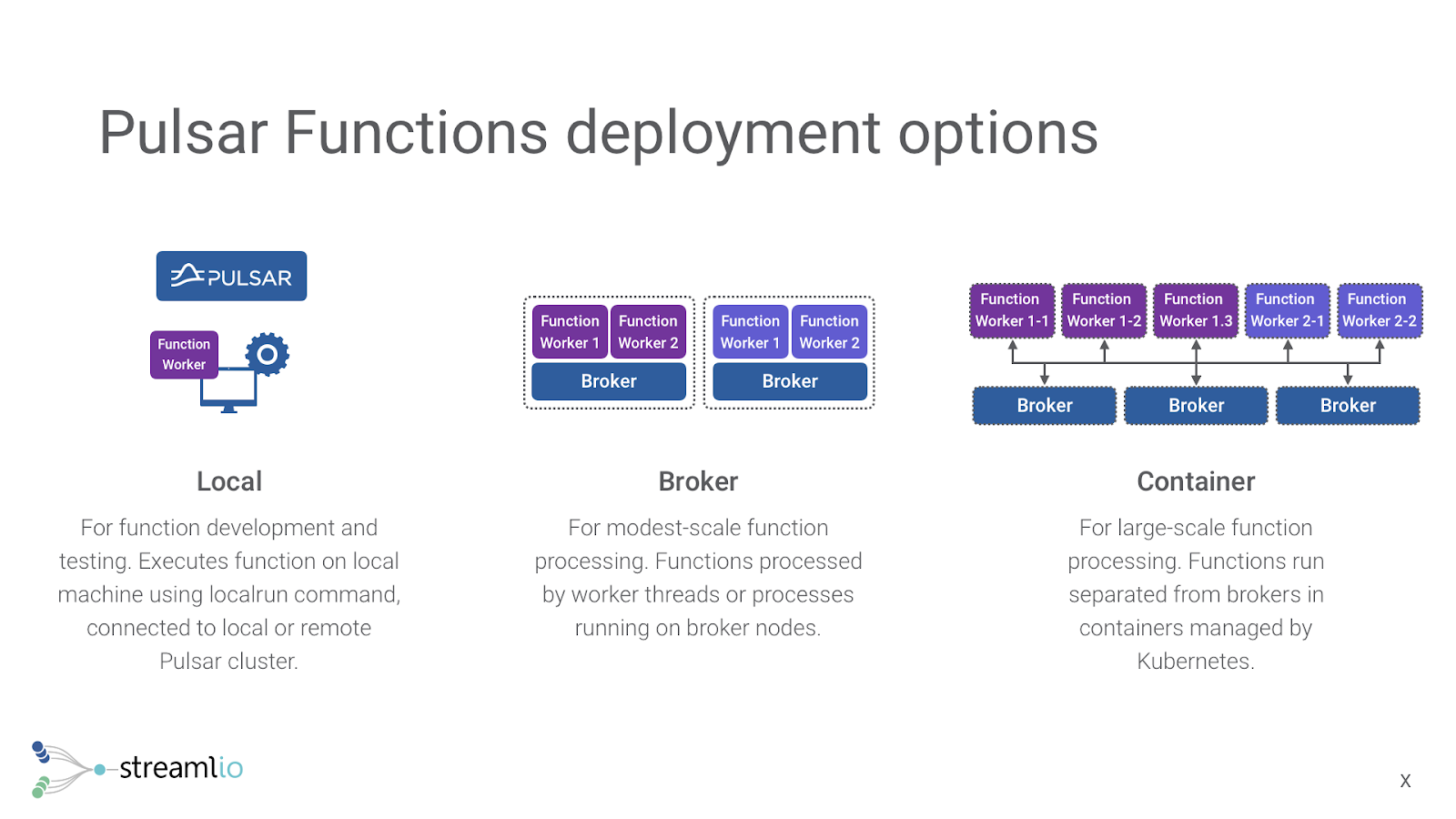
Focusing with Pulsar Functions
Pulsar Functions is a way of running a custom function on data in Apache Pulsar. The functions run in a highly-available cluster that is separate from Pulsar, but is connected to it.
Here is some sample code that adds an exclamation mark to a message:
import java.util.Function;
public class ExclamationFunction implements Function<String, String> {
@Override
public String apply(String input) {
return String.format(“%s!”, input);
}
}
You’ll notice that this code doesn’t contain the boilerplate code that we are trying to eliminate. Pulsar is handling the input topic, deserialization, output topic and serialization. You can quickly read through all of the code and see that we’re taking the input string, add an exclamation mark, and returning the resulting string. The Pulsar Functions framework handled the rest.
Although this code is written in Java, Pulsar Functions supports Python too.
That leaves us with specifying the input and output topics. We make these configurations at runtime as we start the function. From the command line, that looks like:
bin/pulsar-admin functions create \
–inputs persistent://sample/standalone/ns1/test_src \
–output persistent://sample/standalone/ns1/test_result \
–jar examples/api-examples.jar \
–className org.apache.pulsar.functions.api.examples.ExclamationFunction \
–name myFunction=
You can use a YAML file too. This is my preferred option because now there is a file that gets checked into source control that specifies the input and output topics. That YAML file looks like:
inputs: persistent://sample/standalone/ns1/test_src
output: persistent://sample/standalone/ns1/test_result
jar: examples/api-examples.jar
className: org.apache.pulsar.functions.api.examples.ExclamationFunction
name: myFunction
You can start the function with this command line:
bin/pulsar-admin functions create \
–configFile /path/to/my-function-config.yaml
What’s missing operationally doesn’t really stand out here. You are no longer having to worry about where the function is running. This is really key because you aren’t having to create a Docker container or Dockerfile just to run a simple ETL. You just specify the parameters and Pulsar Functions takes care of the rest.
But Wait…That’s Not All..It Slices, It Dices, It Stores Data
If you’ve ever done a stateful, real-time project, you know how difficult that is. With Pulsar there’s a big trick up its sleeve in the form of BookKeeper. BookKeeper isn’t limited to storing commit log files from Pulsar. It can store other data like a global, mutable table.
Table based lookups are often what we need for doing real-time lookups. Pulsar Functions directly and seamlessly integrates with BookKeeper. The API gives you the ability to store and mutate state based on a key. Better yet, this state is efficient and global.
Without going into detail (this is a future post), Kafka stateful option for Kafka Streams has some missing features that put a huge operational difficult on you. BookKeeper solves this issue in a much better way.
Reducing Operational Overhead
As you’ve seen, Pulsar Functions really reduces the operational overhead. We allow our developers to just focus on writing the code that matters – your custom code – and not the boilerplate code. It keeps your developers from having to think about the containers, etc just to deploy a simple ETL process.
It helps the operations team by having a single place where the message and stream processing code lives. It makes the operations teams’ lives much easier with stateful streaming.
Take a close look and see how your team could start focusing more on the code and less on the operations side.
Full disclosure: this post was supported by Streamlio. Streamlio provides a solution powered by Apache Pulsar and other open source technologies.